(部分的)リスタートの意義
これまでのまとめ
- First UIP distribution (2019-07-21)
- Development of Var activities (2019-07-11)
- Some Stats about Partial Restart (2019-08-04)
求解状況の平滑化された数値化を実現して、それをリスタートに反映させようとしてきた。 しかし、リスタートは本当に必要なのだろうか。 途中で打ち切るという非連続な、余計なものを持ち込むから制御が複雑怪奇になるのであって、 適切なバックトラックレベルの計算の中に部分的リスタートとして組み込んでしまえばいいだけではなかろうか。
何故なら、ランダムウォークよりもクラスタ(部分問題を構成する変数集合)間の遷移モデルの方がよさそうだから。
- クラスタから出ないように(そのためにはリスタートは掛けない)、部分的リスタートを実行
- 停滞したら大きくジャンプして次のクラスタを探す
- クラスタを定義する候補の一つが割り当て履歴に依存する First UIP 集合。 これは定義から、他のクラスタとのリンクを切る可能性を持つ変数である。 それらを集めればこれは非常によい局所性を示すようになるのではなかろうか。
この仮定が正しいなら、変数の最終割当てと求解対象のクラスタの時刻分布 は相関を示すはずだし、それはリスタートにより離散クラスタ的な傾向を示すはず。 与えられた問題はクラスタを解きながら(部分的)リスタートによって遷移することで解けるだろう。
ただ、ここの「変数割当て」というのは定義が難しい。 割当てが決定したと言いたいのだろうが他の変数のためのバックトラックによって簡単に壊れてしまう。 部分問題ではなく全体での割り当てならそれは最後のバックトラック以降だけしか見ないことになる。
結局、その意味するものはDevelopment of Var activities (2019-07-11)で考えた 変数活性度の分散、あるいはその近似のFUP集合の大きさに帰着するようだ。
この結果を(部分的)リスタートに反映させた戦略を実装評価すべきである。 ということでSome Stats about Partial Restart (2019-08-04)で実装を試し てみたのだが、いい成果にはならなかった。
2019-08-20
およそ一ヶ月間ずっとscrap and buildを繰り返して、そこそこの実証も得られた。
リテラルaからリテラルbを導出する手間とその逆の手間は同じではない。オーダーレベルで違う。 だからリスタートには意味がある。
問題が疎なクラスタに分割できるとすると、UNSAT問題はUNSATなクラスタを見つけることが必要。 SATクラスタは実は求解には寄与しない(がもちろん前もって知ることは不可能)。
現在のrewarding & phase-savingの副産物としてハードクラスタに当たると割り当て数は減少する。 これは矛盾している部分から割り当てようとするため。 その結果クラスタに高い確率で含まれる変数であっても矛盾解消の時点で割り当てがなくなることがある。 クラスタを維持するという目的に関しては部分的リスタートの効果は疑問。
クラスタは閉集合ではない。割り当て対象リテラルをクラスタに含まれないものから取れば明らかに漸増する。 その不動点は問題を構成する閉集合そのものになってしまう。
にも関わらず、その増え方には特徴が見られる。 明らかな拡大期と停滞期からなる問題もあれば、定常的に増大する問題もある。 変数数が少ない3SAT問題などでは短期間で極大化してしまう。
停滞期は難しいクラスタに突っ込んだ状態と考えてよい。 停滞期に至るまでに解けなかったなら解くべき問題は他にあると考えるべきか。 実験結果はこの方向性を強く示唆しているようだ。
2019-08-24
さらにscrap and build。
EMAベースのLBDによる枝刈りはそれなりに説得力ある。なんといっても時間平均値だから。 しかし、学習節の評価と求解打ち切りの尺度の関係がいまひとつ不明な気がする。 ハードクラスタに突入したからリスタートをかけたいのなら、目的と手段の間にズレが生じているのではないか。 手間がかかり過ぎる、すなわち大きなクラスタに突入したことをもってリスタートの契機にすべきでは。
求解中はリスタートを禁止し、時間超過の場合のみリスタートをするならば、割当量とLBDという2種類の評価尺度を持ち出す必要はなくなり、より簡潔なものになる。
2019-08-28
名前よくねーな、restartではなくreorderingじゃねーか。variable rewardingはpivot selectingじゃん。
リスタートは思ったほどリセットではない。よくよく気づいてなかったけど、 例えば以下の時間変化の図からわかるように少なくともFUPやCNFに関してはリスタートの実行はほとんど影響を与えない。 むしろ同一セグメントを形成するのかもしれない。個人的にはちょっとショックだったがよくよく考えれば、 求解中にリスタートを掛けても対象となる矛盾リテラルは(多くの場合)変わらないはずでこの観測結果を裏付ける。 ハードコア内での積極的なリスタートは割当て順序の入れ替えという意味で積極的に行ってもいいのかもしれない。
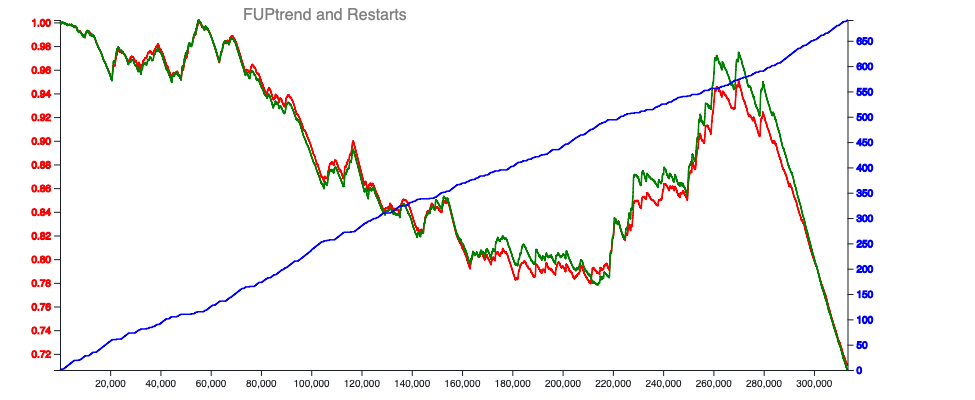
図に示された観測結果はFUPが時間積算値であり、しかもEMA平均を取っているせいだろう。ここがLBDや割当量とは大きく違うところ。
リスタートの説明としては、割当ての試みの順序が変わるのだから計算量に影響を及ぼすような変動をもたらす。 一方で、探索対象の変数群に関しては大きな変更はもたらさない。というところではないか。 履歴依存性というか、順序付けが重要な探索問題なので、探索ではなく並べ替え問題と理解したほうがいいかも。
また、最近restartに導入した評価値の量子化のせいかもしれない。リスタートの変動が吸収されているかも。
一方、FUP拡張期でのリスタートはどういう意味があるのだろう。 停滞期のリスタートがハードコアの矛盾解消のための並べ替えだとすると、こちらはコア間の並べ替えではなかろうか。
面白いのは拡張期においてもFUPやCNF(のトレンド)に影響を与えてないように見える点である。 FULトレンドが、言うなればスコープを与えるもの(実際はその逆でスコープから決まる量)だとすると拡張期により広い範囲での並べ替えをしようとしていると考えるのは自然だろう。
2019-09-03 Restart-As-Swapping-FULs
give up中。
大域的な尺度が出たとしてそれをどう使えばよいかわからない。 動作選択指針となり得るオンラインでかつ履歴に(それほど)依存しない尺度の方が使い勝手がいいと言われればそれまでのような。
そもそもLBDやASGが激しく暴れるのはその局面の評価をしたいからであって、大域的な傾向が知りたいわけではないのだから、むしろ当然なのだろう。 ただなぜ長さ25なのかという疑問は残るが、まあ、サンプリング精度はそれほど結果に影響を与えないのだろうから、ここに突っ込んでもしょうがない。
ということからローカルな尺度 + リスタートの意義を反映した変数の重み付け が重要な気がしてきた。 この視点から見てCHBはどうなんだろうか。 複雑すぎやしないだろうか。 このところの結論は、「変数の優先度とは要は順序づけ」なのだが、ここに指数関数、EMAを導入する必要があるだろうか。
2019-09-10
一時撤退。もう一度0.1.3から組み立て直してみると、block restartやforce restartのタイミングは 非常に微妙で、ちょっと変更しただけで大きな差が生じていた。0.2.0に向けてのリファクタリングは、 アルゴリズムの変更よりも影響が大きそうなので、一旦0.1.4をリリースしてから再挑戦した方がいい ようだ。で、今のところリスタートの意義を反映した変数の重み付け はうまくいっていない。
- ASGの値を基にしたblock_restartを呼び出すのはコンフリクトが起きたタイミング。 まあ、できる単位伝播が残っているのにASGを更新しても意味がないかもしれない。 だとすると判定呼び出しの場所として合理的なのはコンフリクトが起きた直後ということになる。 うーむ、一つの前のpropagateでの到達割当て数を記録すべきだろうか。
- LBDの値を基にしたforce_restartを呼び出すのはコンフリクトが起きてない決定レベル上昇中。 これもリスタートが起きないパスで強制的にリスタートをするのが目的だとすればそうかもしれない。 判断の最適化はしたとしても、判定呼び出しの場所はここでないといけないようだ。
というわけで、どちらのタイミングも0.2.0RCでは完全にひっくり返っていた。ちょっと確かめた範囲では このロジックの無視(反転)は明らかな性能劣化を起こしていた。
さらにVISDSのオーバーフロー対策のスケーリング係数も意外に大きく効く。 実際に丸め誤差が生じているのだろう。ここも0.1.3のコードを修正するなら実験に基づいた設定が必要。